AI内容污染中文互联网:平台治理与模型崩溃
AI 泔水淹没中文互联网——从小红书虚假账号矩阵到微信清理非真人创作,平台治理与模型崩溃的双重危机。
最近,一张微信群截图在各个圈子里疯传。
截图里,有人坦然自爆:用 AI 在小红书搭建了一个庞大的虚假账号矩阵,批量生产内容,最终靠卖号变现。语气之轻松,仿佛在分享一个再正常不过的商业模式。
这张截图之所以让人脊背发凉,不是因为手段有多高明,而是因为它印证了一种越来越强烈的直觉——你刷手机的时候,已经越来越分不清对面是真人在说话,还是机器在表演。
一、从"一个人"到"一片海"
这个自爆的灰产玩家,只是冰山浮出水面的那一个角。
MCN 机构利用 AI 程序,一天能产出上千篇虚假新闻;小说平台的某个账号,靠 AI "创作"每天更新十几本电子书,月更字数上千万——尽管行文逻辑不通、辞藻空洞;更有甚者,有顶尖高校学者在 SCI 发表论文,因为插图由 AI 生成且错误百出,仅 3 天就被撤稿,沦为学界笑柄。
这些不是孤例。它们指向同一个趋势:AI 正在以工业化的规模,重塑互联网内容的生产方式——不是优化,是替代;不是辅助,是接管。
而"接管"之后的结果,不是内容更丰富了,是互联网被"泔水"淹了。

二、有个词叫"AI slop"
英语世界里,人们给这种现象起了一个精准到刻薄的名字:AI slop。
"slop"本意是泔水、猪食。用它来形容 AI 生成的内容,再贴切不过——量大、廉价、勉强能看、吃了没营养。
维基百科专门收录了这个词条。BBC 在 2026 年 2 月的报道中指出,AI slop 正在全面改造社交媒体的内容生态,用户开始集体反弹。有创作者直言:"我不是教条地反对 AI,我反对的是为了骗流量而制造的 AI 污染。"
全球范围内,情况只会更糟。研究数据显示,2023 年社交媒体上流通的深度伪造视频约 50 万个,到 2025 年预计激增至 800 万个。约四分之一的互联网流量来自"bad bots"——恶意机器人,它们的目标是散布虚假信息、操纵舆论、窃取数据。
哈佛大学肯尼迪学院旗下 Misinformation Review 的一项研究发现,一些利用 AI 生成图片的 Facebook 页面群组,平均粉丝数超过 14 万。这些页面由同一批管理员运营,用 AI 批量制造吸引眼球的内容来快速涨粉。
这不是创作,这是信息领域的工业排污。
三、中文互联网的重灾区
回到国内。中文互联网的 AI 污染,有自己独特的"中国特色"。
小红书是重灾区中的重灾区。 这个以"真实分享"为核心价值的社区,正在被 AI 批量制造的虚假种草笔记、虚构消费体验、伪造人设的虚拟账号疯狂入侵。有运营者用 AI 工具实现了"1 人管理 50 个小红书账号"的流水线作业——找爆文、改写、配图、发布,全流程自动化。
你看到的那些"真诚分享",可能来自同一个机房里的同一套脚本。
更讽刺的是,这些灰产玩家甚至已经把 AI 做号做成了一门成熟生意:起号、养号、卖号,形成了完整的产业链。有人用 AI Agent 管理的小红书账号,14 天狂吸 5000 粉,然后直接出售。
当"真实"成为一种可以批量伪造的商品,信任就成了最先被消耗的资源。
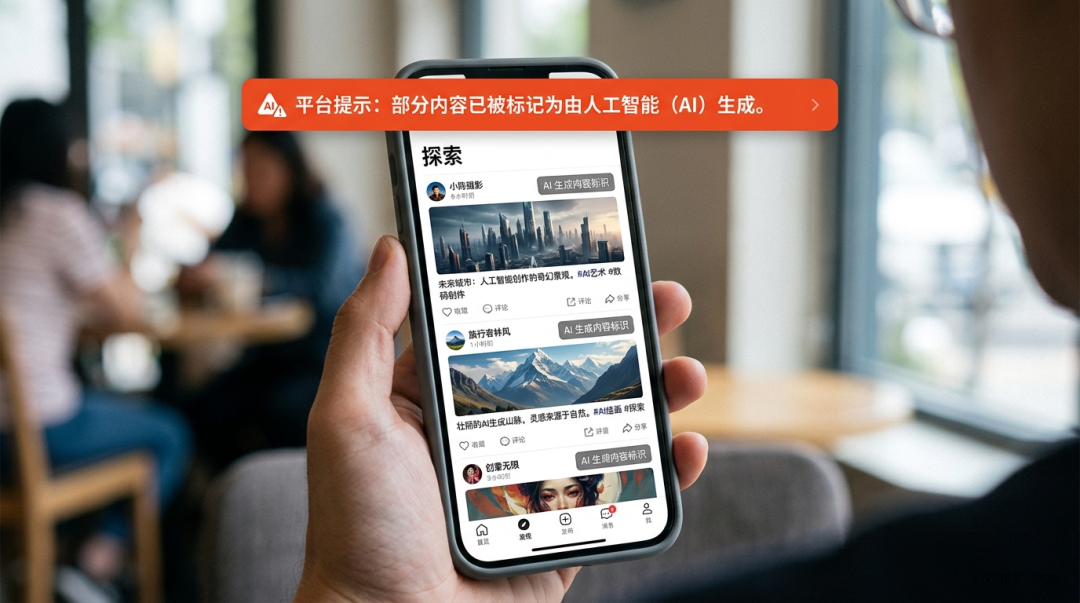
微信也没能幸免。
2026 年 4 月,微信公众平台大规模删除涉嫌"非真人自动化创作"的文章,大量账号被封禁。据第一财经报道,微信团队确认更新了《微信公众平台运营规范》,明确禁止利用 AI、脚本等自动化方式替代真人创作。
这个动作的背后,不仅仅是内容质量的焦虑。公众号沉淀的海量高质量图文,是腾讯独有的知识库,直接决定了腾讯元宝等 AI 产品的竞争力。
如果任由低质 AI 内容污染微信内容池,腾讯在大模型竞争中就会失去最核心的差异化优势。
所以微信不只是在管内容,是在保护自己的护城河。
四、平台开始反击
灰产跑得太快,平台终于坐不住了。
2026 年 2 月,小红书薯管家发布 AI 内容治理公告,明确要求站内 AI 生成的图文、视频必须主动添加标识,未按要求标识的内容将被平台自动补标并限制分发。4 月 27 日,小红书进一步发布 AI 治理规则,明确禁止四类行为:AI 违规运营、AI 造假、AI 洗稿、AI 仿冒。
微信同期更新运营规范,对"非真人自动化创作"重拳出击。
中央网信办在 2026 年春节期间启动"清朗"专项行动,将 AI 技术带来的负面影响列为重点打击对象。
新华社更是直接发文,题为《清除 AI"数字泔水" 以"治"促"智"》,定调之高、措辞之严厉,在近年来的科技报道中罕见。
平台治理的逻辑正在从"事后删帖"转向"源头管控"。
但这恰恰引出了一个更深层的问题:当 AI 生成的内容和真人创作的内容在质量上越来越难区分,"管控"本身还能靠什么?
靠算法识别 AI?那算法本身也是 AI。
五、"模型崩溃"才是终极恐惧
比内容污染更可怕的,是"模型崩溃"(model collapse)。
这是一个已经被学术界验证的现象:当 AI 模型用 AI 生成的内容进行训练时,输出质量会逐代衰减。就像一个复印机反复复印同一份文件,最终得到的是一张什么都看不清的废纸。
国际 AI 安全报告 2026 年版指出,许多常见的 AI 能力评估已经受到"数据污染"的影响——因为训练数据中混入了大量 AI 生成的内容。
这意味着:如果互联网上的内容被 AI 大面积污染,那么下一代的 AI 模型就会在污染的数据上训练,产出更差的内容,再被下一代模型训练……形成一条自我强化的退化螺旋。
互联网不再是一个知识不断累积的公共资源库,而变成了一条越流越脏的河。

六、我的判断
很多人问:AI 到底是在创造还是在毁灭?
我的看法是:工具本身没有善恶,但规模化地降低作恶成本,本身就是一种恶。
过去,造 1000 个虚假账号需要雇 100 个人干一个月。现在,一个人加一套 AI 脚本,一个下午就搞定了。成本从"高"变成了"近乎为零",门槛从"专业团队"变成了"任何人"。
这种不对称的破坏力,才是 AI 污染真正危险的地方。
平台的治理措施当然必要,但本质上都是在下游拦垃圾。只要上游的 AI 工具不对生成规模和用途做任何限制,垃圾只会越拦越多。
而普通人能做的,可能只剩下一件事:保持怀疑。
下次刷到一篇完美的种草笔记、一段情绪饱满的分享、一张无可挑剔的图片——先问一句:这是人写的,还是机器算的?
这个问题本身,可能就是我们对互联网最后的抵抗。
评论
发表评论