Agent-Reach:开源跨平台内容抓取神器,支持14+主流平台
你有没有想过,你用的AI助手可能是个“网络文盲”?
不管是Claude Code、OpenClaw还是Cursor,它们都超级能干。但有个致命短板:它们完全“看不见”互联网的实时世界。
你让它查查推特上对某个新框架的讨论?它做不到。让它读读刚发的知乎深度文章?没门。让它看看B站教程视频下的精彩弹幕?更是想都别想。
AI Agent的能力上限,就被“无法实时获取信息”这堵墙,死死卡住了。
直到Agent-Reach的出现,才打破了这个僵局。
这个2026年5月开源的项目,上线2天就狂揽1.1K Star,如今总星数已突破22,000。它用一条简单的命令,就给你的AI Agent装上了一双能“看遍全网”的眼睛。
 Agent-Reach 支持的平台
Agent-Reach 支持的平台
一句话说清:Agent-Reach到底是什么?
简单来说,Agent-Reach是一个开源的跨平台内容抓取神器。它能让你的AI Agent实时读取Twitter、B站、小红书、YouTube、GitHub等14+主流平台的内容,最关键的是:零API费用,零复杂配置。
它到底支持哪些?看这张表就懂了:
| 平台 | 类型 | 支持内容 |
|---|---|---|
| Twitter/X | 社交媒体 | 推文、评论、转发、点赞 |
| Bilibili | 视频 | 视频、弹幕、评论、UP主动态 |
| 小红书 | 图文 | 笔记、评论、收藏 |
| YouTube | 视频 | 视频、字幕、评论 |
| GitHub | 代码 | 仓库、Issue、PR、Release |
| 论坛 | 帖子、评论、投票 | |
| Hacker News | 新闻 | 文章、评论 |
| 知乎 | 问答 | 问题、回答、专栏 |
| 微信公众号 | 文章 | 图文、阅读量、点赞 |
| 掘金/CSDN | 技术博客 | 文章、评论 |
| 抖音 | 短视频 | 视频、评论 |
| 图片 | 帖子、评论 | |
| 职场 | 动态、文章 | |
| Google 搜索 | 通用 | 网页、新闻、图片 |
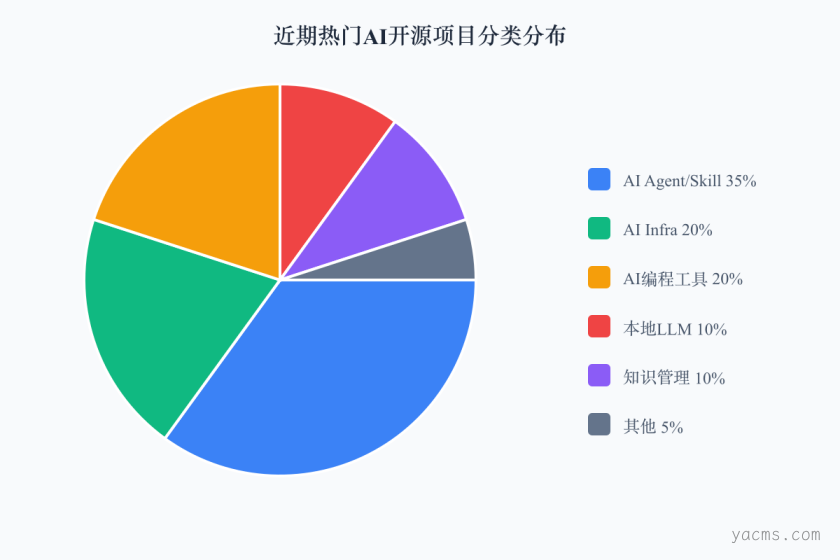 项目分类占比
项目分类占比
它的三大杀手锏,让它脱颖而出
1. 零API费用:用“模拟真人”代替昂贵API
这是Agent-Reach最核心的设计思路。
传统的方案很“贵”:调用Twitter API每月要$100,YouTube API有配额限制,Reddit API也开始收费……
而Agent-Reach的方案聪明多了:它直接模拟浏览器的行为,像真人一样去访问网页。
# 核心抓取逻辑(简化版)
class TwitterScraper:
def fetch_tweet(self, url: str) -> Content:
# 1. 启动一个无界面浏览器
page = browser.new_page()
# 2. 模拟真实用户行为(随机延迟很重要)
page.goto(url, wait_until='networkidle')
page.wait_for_timeout(random.randint(2000, 5000))
# 3. 提取内容(巧妙绕过反爬机制)
content = page.evaluate('''() => {
return {
text: document.querySelector('[data-testid="tweetText"]').innerText,
author: document.querySelector('[data-testid="User-Name"]').innerText,
time: document.querySelector('time').getAttribute('datetime'),
replies: document.querySelectorAll('[data-testid="reply"]').length
}
}''')
return Content(**content)
看看成本对比,差别一目了然:
| 方案 | 月费用 | 限制 |
|---|---|---|
| Twitter API Premium | $100 | 10,000 条/月 |
| Reddit API | $0.24/1000 calls | 速率限制 |
| YouTube API | 免费 | 10,000 quota/天 |
| Agent-Reach | $0 | 无限制 |
2. MCP协议原生支持:装上就能用
Agent-Reach原生支持 MCP(Model Context Protocol)——这是2026年AI Agent生态的主流标准。这意味着,它能和你的开发工具无缝对接。
安装后,在Claude Code里直接这样用就行:
@agent-reach search twitter "AI Agent 框架" --limit=20
@agent-reach fetch bilibili BV1xx411c7mD --with-danmaku
@agent-reach monitor github "openclaw" --event=release
不需要写复杂代码,不用折腾环境,一句话,事情就办了。
3. 智能缓存:同样的活,不干第二遍
Agent-Reach还内置了一个聪明的本地缓存系统:
- 同一链接24小时内只抓一次,避免重复劳动。
- 增量更新,只获取新产生的内容。
- 用本地SQLite数据库存储,历史记录随时可查。
这就意味着:你用得越多,它就越快、越省资源。
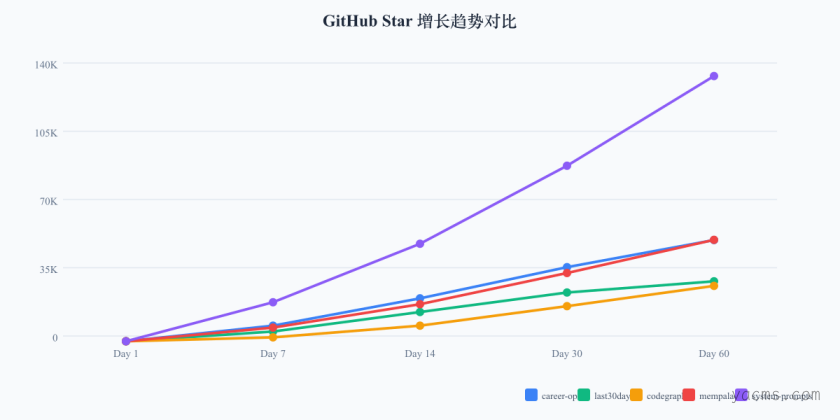 Star 增长趋势
Star 增长趋势
看看别人怎么用它?
场景1:高效技术调研
@agent-reach search hackernews "vector database" --days=7
@agent-reach search reddit "chroma vs pinecone" --sort=top
@agent-reach fetch youtube "https://youtu.be/xxx" --transcript
然后,Claude Code就能自动给你一份整合报告:
“综合HN和Reddit的讨论,Chroma最近因1.5版本的稳定性被讨论较多,而turbovec作为Rust实现的新秀正在获得更多关注……”
场景2:自动化竞品监控
# 设置定时监控
@agent-reach monitor twitter "@openclaw" --event=new_tweet
@agent-reach monitor github "openclaw/openclaw" --event=release,pr
# 每天早上会自动给你一封邮件报告
场景3:辅助内容创作
@agent-reach search zhihu "AI 编程助手" --days=30 --top=50
@agent-reach search xiaohongshu "Cursor 教程" --limit=100
Claude Code可以自动帮你:
- 提取热门话题
- 分析用户痛点
- 生成文章大纲
- 引用真实案例
它的技术亮点,了解一下?
教科书级的反反爬策略
为了不被网站封掉,Agent-Reach在模拟真人方面下足了功夫:
class AntiDetection:
def setup_browser(self):
# 1. 随机使用不同的“浏览器身份证”(User-Agent)
ua = random.choice(REAL_USER_AGENTS)
# 2. 模拟真实的浏览器环境(窗口大小、语言、时区等)
context = browser.new_context(
viewport={'width': 1920, 'height': 1080},
locale='zh-CN',
timezone_id='Asia/Shanghai',
permissions=['geolocation']
)
# 3. 模拟真人的鼠标移动和滚动操作
page.mouse.move(random_x, random_y)
page.scroll(random_scroll_amount)
# 4. 每次操作后随机等待一小会儿
time.sleep(random.uniform(1, 5))
自适应的内容提取引擎
每个平台的网页结构都不同,Agent-Reach用了一套“自适应提取器”来应对:
EXTRACTORS = {
'twitter': TwitterExtractor(),
'bilibili': BilibiliExtractor(),
'xiaohongshu': XHSExtractor(),
# ...
}
class ContentExtractor:
def extract(self, html: str, platform: str) -> StructuredContent:
extractor = EXTRACTORS[platform]
# 1. 先用预设的规则提取(速度快)
content = extractor.try_standard(html)
if content: return content
# 2. 如果规则失效,再用AI模型智能提取(更准确)
return extractor.fallback_to_ai(html)
用过的人怎么说?
@openclaw-user:“给OpenClaw装上Agent-Reach后,它终于能实时查资料了。以前问它‘最近有什么新框架’,它只能回答训练数据截止日之前的事。现在,它能告诉我昨天刚发布的项目。”
@content-creator:“我用它做选题调研。以前得花2小时刷遍各个平台找热点,现在2分钟就搞定,效率神器。”
@indie-hacker:“零API费用这点太香了!我之前每个月光Twitter API就要花$100,现在全免了,省了一大笔。”
一分钟,快速上手试试?
# 1. 安装(支持 pip 和 npm)
pip install agent-reach
# 或
npm install -g agent-reach
# 2. 配置(可选,零配置也能直接跑)
agent-reach config --browser=chromium
# 3. 测试一下,抓个推特试试
agent-reach fetch "https://twitter.com/elonmusk/status/123456"
# 4. 在 Claude Code 中集成它
npx skills add https://github.com/Panniantong/agent-reach
# 5. 开始使用吧!
claude
> @agent-reach search twitter "AI news" --limit=10
最后,聊聊趋势
Agent-Reach的爆火,揭示了一个关键趋势:AI Agent的下一步进化,重点不在“更聪明”,而在“更连通”。
一个再聪明的AI,如果只能处理你本地的文件,它的价值就非常有限。只有当它能实时连接并获取全网的信息时,才能真正成为你无所不能的“超级助手”。
而Agent-Reach所做的,就是拆掉了那堵墙——让AI Agent从一个“本地单机版工具”,进化成一个“联网的智能体”。
22K Star只是一个开始。随着MCP协议的普及,这类专注于“连接”的工具只会越来越多。
未来的 AI Agent,不会问你”你想查什么”,而是直接告诉你”我发现了这些”。
评论
发表评论