智谱很好,9:11发布了GLM-5.2,作为研发需要关注什么

今天上午09:11分,智谱(Z.ai)正式发布新一代旗舰模型 GLM-5.2,并在 Hugging Face、ModelScope 以 MIT 协议开源权重。
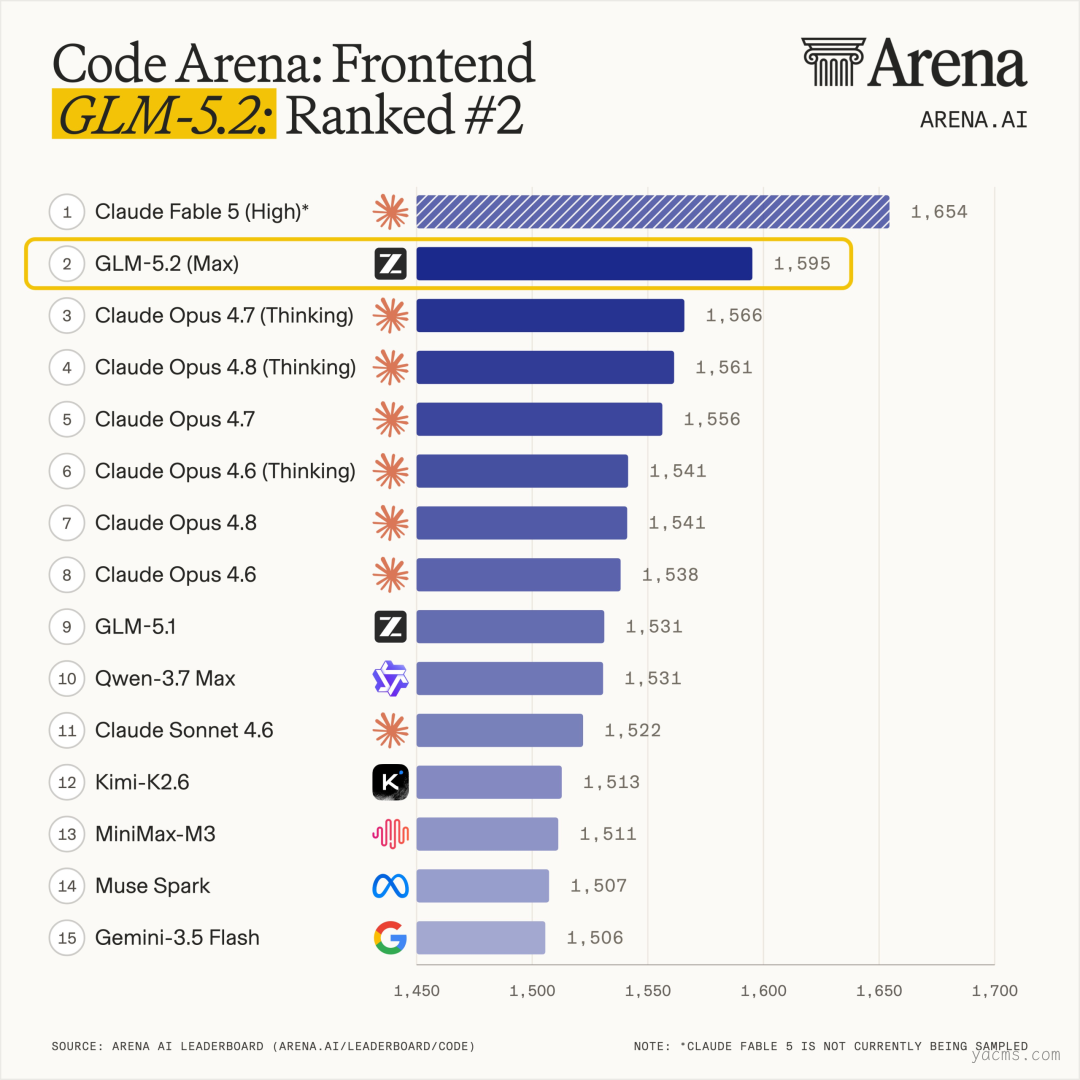
在Code Arena上,GLM-5.2取得全球可用模型第一的优异表现
对一线研发来说,这不是又一条「模型上新」的新闻——它意味着:开源阵营在长程编程场景上,正在系统性逼近闭源前沿。
如果你负责技术选型、AI 基建或日常写码辅助,下面三件事值得立刻放进观察清单。
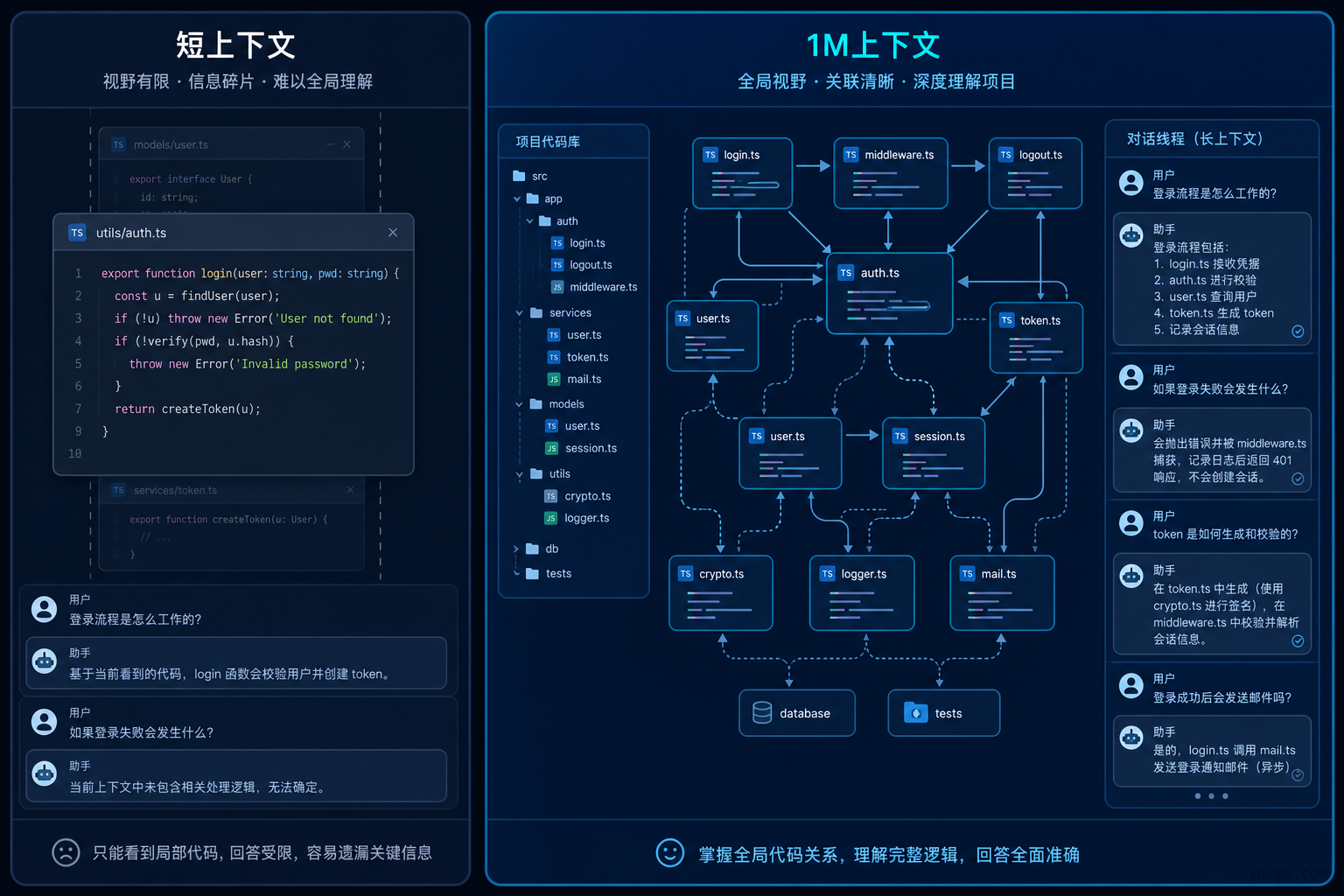
一、1M 上下文:长程 Agent 的「硬门槛」松动了
GLM-5.2 把可用上下文推到 1M tokens,最大输出 128K。相比 GLM-5.1 约 200K 的级别,这不是纸面参数,而是面向「整仓代码 + 长对话轨迹」的工程升级。
官方引入 IndexShare 架构:每 4 层稀疏注意力共享一个轻量 indexer,在 1M 长度下将 per-token FLOPs 降低约 2.9 倍。简单说,长上下文不再只是「能塞进去」,而是更接近「跑得动」。
对研发的实际影响:
- 大型单体仓库 / 微服务群的跨文件改动,上下文瓶颈明显缓解
- 多轮 Agent 任务(修 bug → 跑测试 → 再改)更少「失忆」
- 需要自行验证:你团队的真实代码库体积、推理框架是否已支持 1M(vLLM 0.23+、SGLang 0.5.13+ 等,以官方文档为准)
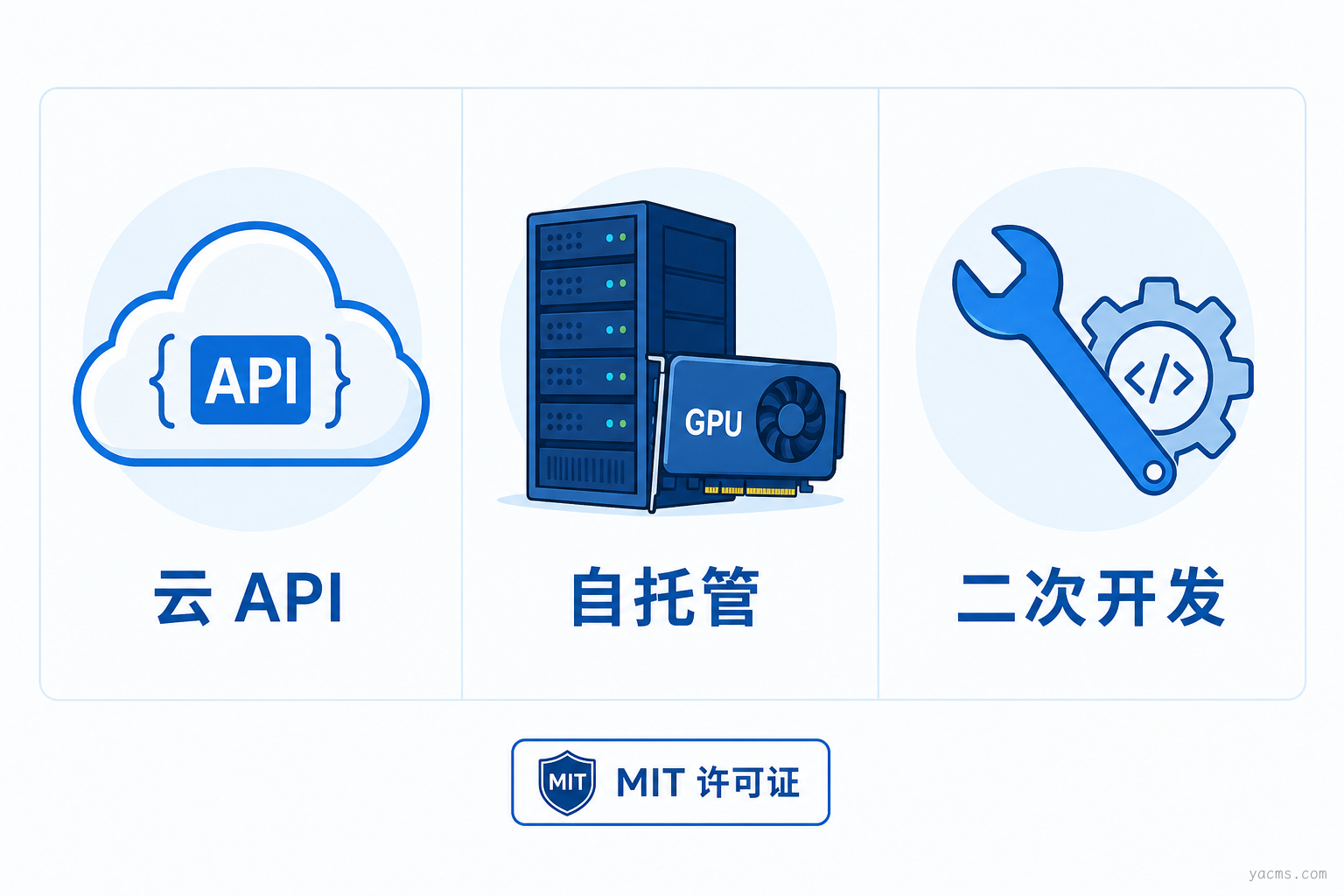
二、MIT 开源:合规与自托管的选项变宽了
GLM-5.2 采用 MIT License——可下载、修改、商用,无地域限制条款。这在当前大模型许可环境里并不常见。
对研发与架构团队,这意味着三条路径同时成立:
- 云 API:通过 Z.ai API 或智谱开放平台快速接入
- 自托管:从 Hugging Face 拉权重,在自有 GPU / 国产算力上部署
- 二次开发:微调、蒸馏、内网定制——许可层面阻力小
媒体报道显示,GLM-5.2 在发布首日即完成与华为昇腾、摩尔线程、寒武纪等 国产算力平台的适配。若你所在团队有国产化部署要求,这是比 benchmark 分数更现实的加分项。
三、编程 benchmark:与闭源前沿的差距缩小到个位数
先看官方模型卡上的几组数字(统计时点:2026-06,来源:Hugging Face GLM-5.2):
| 基准 | GLM-5.2 | Claude Opus 4.8 |
|---|---|---|
| Terminal Bench 2.1 | 81.0 | 85.0 |
| SWE-bench Pro | 62.1 | 69.2 |
| FrontierSWE | 74.4 | 75.1 |
在 Terminal Bench 这类长程终端任务上,GLM-5.2 得分 81.0,为目前已公开的开源模型中较高水平;与 Claude Opus 4.8(85.0)差距约 4 个百分点。SWE-bench Pro 仍有距离,但 FrontierSWE 已非常接近。
需要冷静看待的是:榜单 ≠ 你的业务场景。前端、后端、基础设施的技术栈差异很大,Code Arena 等盲测里 GLM-5.2 在前端开发场景表现突出(媒体报道),不代表所有工程任务通吃。
研发该做的不是「换模型信仰」,而是 用自家仓库做小规模 A/B:同一组 issue、同一套测试,对比延迟、成本、通过率。
落地建议:别急着 all in,先建立可切换能力
结合以上三点,给研发团队的行动清单:
- 申请 API 试用:GLM Coding Plan 用户已可优先体验;关注 peak / off-peak 计费倍率(官方说明 off-peak 有促销,以控制台为准)
- 评估自托管成本:753B MoE 不是笔记本能跑的体量,先算清 GPU 集群与推理框架选型
- 保留多模型路由:开源 MIT + 闭源 API 并存,按任务类型(长上下文 / 快速补全 / 安全审计)分流
- 跟踪国产算力适配:若有信创要求,Day 0 适配清单值得与基础设施同事同步

写在最后
GLM-5.2 的核心信号很清晰:开源旗舰正在长程编程场景上逼近闭源天花板,同时用 MIT 把选择权还给开发者。
对研发而言,关注 GLM-5.2 不是为了追热点,而是审视自己的 AI 工具链——是否具备「随时切换底座、按场景选模型」的弹性。这才是 2026 年技术团队真正的护城河。
信息来源:
GLM-5.2上线并开源:专注Coding与长程任务
你觉得发布时间是不是巧合?
觉得有用?点个关注,持续获取优质内容。
评论
发表评论